You may want to check out this unique event.
[will return to the declaration shortly]
Tuesday, March 31, 2009
Saturday, March 28, 2009
Window-on-Data applications
Up till now I have been focussing on technology. We have seen DBMS´s evolve, the web and n-tier architectures come into existence, Yafets prosper, and developer productivity go down the drain. I also spent some time discussing the Java/JEE bandwagon. And used MVC to discuss various technical application architectures. Ohhh, if only there were just technology. Life as an application developer would be so wonderful.
But wait. We have end users too. Shoot...
Let's focus on our customers for a bit: the end users. What is it that they want? Well, I claim that they still want the same (as twenty years ago). In essence that is. They want application frontends that enable them to do their job efficiently. The look & feel of the frontend obviously has evolved (observation two) but they still want to be able to:

Typically the user would enter some search criteria on the page, then hit a search button. The server processes this request and returns data that's then displayed in the 'window'. Sounds familiar?
And the second thing a WoD application enables an end user to do: to transact data.

In this scenario the user navigates through already displayed data, marks some to be deleted, maybe changes some values, or enters new data. Then hits a save button. Server processes this request again, and comes back with message indicating whether the transacation was successful.
I claim that the majority of the "database web applications" that are being built today (in more complex ways every five years), are still these type of applications: applications that enable users to query and/or transact data.
By the way... It might be interesting to note now that DBMS's were born to do exactly this. The number one design criterium for a DBMS is: to query and transact data. This is why DBMS's came about. Another interesting fact to note now is that data can be "modelled" in many ways. After hierarchical (triangular wheels) and network models (square wheels), E.F. Codd gave us the relational model of data. And guess what? The wheel doesn't get any rounder. The relational model of data is the end station. It is how we should develop database designs. Now and in the far future. SQL DBMS's are made to deal with (query and transact) lots and lots of data in a manageable and scalable way. These DBMS's nowadays can do this really good, provided (big if here) the data sits in a sound relational database design. Put in another way: a WoD application should have as its foundation a relational database design, for it to reap the benefits a SQL DBMS can provide.
Now don't tell me that we should model the real world in terms of objects... That to me is just going backwards to a network/hierarhical way of designing the data. Not just that, it also merges (hardwires) data and behavior back together again. History has shown that this creates an inproductive and inflexible status quo.
Let's now gradually start developing the Helsinki declaration (or Helsinki in short). The scope of Helsinki is WoD applications. Which doesn't bother me, as they represent by far the majority of the applications that are being built. By the way, technically a WoD application doesn't require end users. More than once I've been challenged with an application that surely couldn't be classified as a WoD application. But the application in those cases did provide a "window on data". Only the window was used by some other piece of software. That to me is still a WoD application. I may go into this in more detail, when I feel like talking about SOA.
Like JEE, Helsinki also has sort of an MVC classification for code. There are some subtle differences though.

I declare that every line of code that is written to implement a WoD application can be classified into one of these three classes:
Helsinki User Interface (UI) code
All code that you write to:
And you know what? I can actually see how object-oriented programming concepts might help us here. For instance a button object that has a 'when-pushed' method, or a multi-record display grid object that has methods like 'sort on column', 'give next set of records', etc.
Compared to JEE's MVC, Helsinki UI-code equals the V and the C together.
In my presentation I then always skip the Business Logic class, and first tell the audience what Helsinki means by Data Logic (DL) code.
Helsinki DL code
As stated above, a WoD application should be based on a sound relational database design. As a crucial part of that database design we typically will have data integrity constraints. These are assertions that tell us what data is and is not allowed inside the table structures that together make up the database design. When discussing integrity constraints with other people I find there are two tribes.

Actually the SQL standard has the concept of an assertion to implement these other constraints declaratively too. Theoretically what we are dealing with here is predicate logic: boolean expressions over the data held in the table structures that must evaluate to true at all times. Btw. this is a main theme of the book I wrote with Lex de Haan.
In Helsinki every WoD application code line that you write to validate (i.e. guarantee the continued truth of) your data integrity constraints, is classified as a Data Logic code line. In a WoD application, a lot of code will sit in this class and not in the business logic class discussed hereafter.
Compared to JEE's MVC, Helsinki DL-code equals a well defined subset of M.
Ohh, and one final remark: I really fail to see how object orientation can help me implement DL code. This is all set theory and predicate logic: OO concepts just do not fit in here.
Helsinki Business Logic (BL) code
I left this one for last on purpose. This is because I always define business logic code by saying what it is not. In Helsinki, if you write a line of code for a WoD application, and that line of code does not classify as either UI-code nor DL-code, then that line of code must be BL-code. In short BL-code is the rest. If it ain't UI-code and it ain't DL-code, then is must be BL-code.
Now if you prune UI and DL code, you'll see that what is left is either:
Compared to JEE's MVC, Helsinki BL-code equals a well defined subset (the other, remaining part) of M.
Code classes interaction
I'll conclude today's post with a picture of how the three Helsinki code classes interact with eachother.
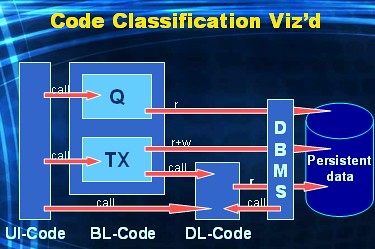
This figure illustrates the following relations between the code classes:
But wait. We have end users too. Shoot...
Let's focus on our customers for a bit: the end users. What is it that they want? Well, I claim that they still want the same (as twenty years ago). In essence that is. They want application frontends that enable them to do their job efficiently. The look & feel of the frontend obviously has evolved (observation two) but they still want to be able to:
- find a customer
- look at the details of that customer
- enter new orders for that customer
- bill that customer
- etc.
Typically the user would enter some search criteria on the page, then hit a search button. The server processes this request and returns data that's then displayed in the 'window'. Sounds familiar?
And the second thing a WoD application enables an end user to do: to transact data.
In this scenario the user navigates through already displayed data, marks some to be deleted, maybe changes some values, or enters new data. Then hits a save button. Server processes this request again, and comes back with message indicating whether the transacation was successful.
I claim that the majority of the "database web applications" that are being built today (in more complex ways every five years), are still these type of applications: applications that enable users to query and/or transact data.
By the way... It might be interesting to note now that DBMS's were born to do exactly this. The number one design criterium for a DBMS is: to query and transact data. This is why DBMS's came about. Another interesting fact to note now is that data can be "modelled" in many ways. After hierarchical (triangular wheels) and network models (square wheels), E.F. Codd gave us the relational model of data. And guess what? The wheel doesn't get any rounder. The relational model of data is the end station. It is how we should develop database designs. Now and in the far future. SQL DBMS's are made to deal with (query and transact) lots and lots of data in a manageable and scalable way. These DBMS's nowadays can do this really good, provided (big if here) the data sits in a sound relational database design. Put in another way: a WoD application should have as its foundation a relational database design, for it to reap the benefits a SQL DBMS can provide.
Now don't tell me that we should model the real world in terms of objects... That to me is just going backwards to a network/hierarhical way of designing the data. Not just that, it also merges (hardwires) data and behavior back together again. History has shown that this creates an inproductive and inflexible status quo.
Let's now gradually start developing the Helsinki declaration (or Helsinki in short). The scope of Helsinki is WoD applications. Which doesn't bother me, as they represent by far the majority of the applications that are being built. By the way, technically a WoD application doesn't require end users. More than once I've been challenged with an application that surely couldn't be classified as a WoD application. But the application in those cases did provide a "window on data". Only the window was used by some other piece of software. That to me is still a WoD application. I may go into this in more detail, when I feel like talking about SOA.
Like JEE, Helsinki also has sort of an MVC classification for code. There are some subtle differences though.
I declare that every line of code that is written to implement a WoD application can be classified into one of these three classes:
- User interface code
- Business logic code
- Data logic code
Helsinki User Interface (UI) code
All code that you write to:
- create user interface that displays row(s) of data, and/or code you write to,
- respond to events triggered by the end user using the user interface, which then typically changes the user interface, most likely after first calling business logic code,
And you know what? I can actually see how object-oriented programming concepts might help us here. For instance a button object that has a 'when-pushed' method, or a multi-record display grid object that has methods like 'sort on column', 'give next set of records', etc.
Compared to JEE's MVC, Helsinki UI-code equals the V and the C together.
In my presentation I then always skip the Business Logic class, and first tell the audience what Helsinki means by Data Logic (DL) code.
Helsinki DL code
As stated above, a WoD application should be based on a sound relational database design. As a crucial part of that database design we typically will have data integrity constraints. These are assertions that tell us what data is and is not allowed inside the table structures that together make up the database design. When discussing integrity constraints with other people I find there are two tribes.
- Those who think all (and no more) that can be dealt with declaratively falls within the realm of a constraint. In Oracle this would result into check constraints, primary keys, unique keys and foreign keys.
- Those who know that there is a broader more generic concept of a constraint introduced in E.F. Codd's relational model of data. SQL implementations just happen to give us declarative constructs for above common constraint types that appear in almost every database design.
Actually the SQL standard has the concept of an assertion to implement these other constraints declaratively too. Theoretically what we are dealing with here is predicate logic: boolean expressions over the data held in the table structures that must evaluate to true at all times. Btw. this is a main theme of the book I wrote with Lex de Haan.
In Helsinki every WoD application code line that you write to validate (i.e. guarantee the continued truth of) your data integrity constraints, is classified as a Data Logic code line. In a WoD application, a lot of code will sit in this class and not in the business logic class discussed hereafter.
Compared to JEE's MVC, Helsinki DL-code equals a well defined subset of M.
Ohh, and one final remark: I really fail to see how object orientation can help me implement DL code. This is all set theory and predicate logic: OO concepts just do not fit in here.
Helsinki Business Logic (BL) code
I left this one for last on purpose. This is because I always define business logic code by saying what it is not. In Helsinki, if you write a line of code for a WoD application, and that line of code does not classify as either UI-code nor DL-code, then that line of code must be BL-code. In short BL-code is the rest. If it ain't UI-code and it ain't DL-code, then is must be BL-code.
Now if you prune UI and DL code, you'll see that what is left is either:
- code that composes and executes queries in a way the business of the end user requires it(I refer to this as read-BL code), or
- code that composes and executes transactions in a way the business of the end user requires it (I refer to this as write-BL code).
Compared to JEE's MVC, Helsinki BL-code equals a well defined subset (the other, remaining part) of M.
Code classes interaction
I'll conclude today's post with a picture of how the three Helsinki code classes interact with eachother.
This figure illustrates the following relations between the code classes:
- UI-code holds calls to rBL-code (queries) or wBL-code (transactions)
- rBL-code holds embedded SELECT statements that read data from the database
- wBL-code holds embedded DML statements that write to the database
- wBL-code often also holds embedded queries reading the database
- DL-code often requires the execution SELECT statements
- DL-code is typically called from wBL-code
- DL-code can also be called by the DBMS via database triggers that fire as a result of the execution of DML-statements originating from wBL-code
- Sometimes you'll see that UI-code calls DL-code directly; this is often done to create a responsive, more user friendly, user interface
Wednesday, March 25, 2009
JEE and traditional MVC (Part 2)
In the previous post I gave a high level introduction into the MVC design pattern. This pattern classifies all code that you write to implement a database web application, into three classes:
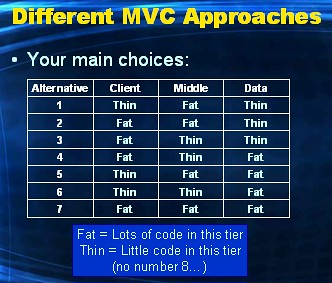
Number eight, Thin-Thin-Thin, is irrelevant and therefor not shown. I'll discuss each of above seven approaches in this post.
Let's start with number 1: Thin-Fat-Thin.
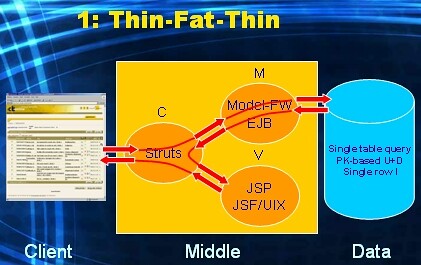
This is the typical JEE way of creating an HTML-based application. And it is I think by far the most popular approach. Control is implemented for instance with some control-framework (used to be Struts, but I think it's Spring nowadays). Model is implemented with EJB or some model framework (in an Oracle environment: ADF-BC). View is implemented with JSP or some view framework (e.g. UIX, JSF, ...). In this approach the browser displays a (poor) HTML GUI (thin), and sends HTTP requests to the controller. The controller then coordinates the execution of EJB code or model framework code. Inside these all business logic and data logic processing has been implemented (fat). Eventually simple (i.e. single table) queries , or simple (i.e. single row, primary-key based) DML statements are executed towards the database (thin). The controller then determines the next page to be sent back and initiates the View framework to do so. Both Control and View hold no business/data logic, since that would violate the MVC design pattern.
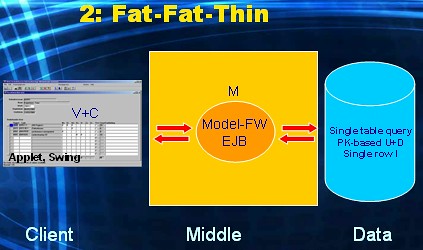
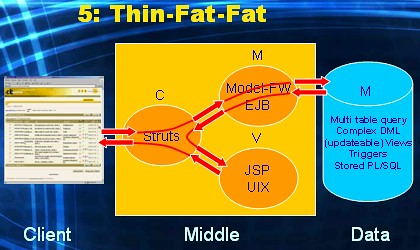
This is "client/server the JEE way". The client-tier runs a fat program (either Applet based, or Java-in-OS based). Control and View are implemented within this fat client-side GUI application. Model is implemented with EJB or some model framework. The client tier is in charge in this alternative (fat): it deals with creating the rich GUI and handling all UI-events (control) on behalf of the user. In this alternative the client delegates the execution of all business logic and data logic processing to EJB code or Model framework code, which is located centrally in the middle tier (fat). The database again only needs to serve simple queries and simple DML-statements (thin) initiated by the fat Model layer. In short, processing for V and C takes place in the Client tier and for M takes place in the Middle tier.
This is "client/server in the early days", pre Oracle7 (when stored pl/sql was not available yet). The application is again either Applet based or Java-in-OS based. The difference with the previous alternative is that all business and data logic is now also implemented within the rich GUI application running on the Client Tier (fat). So not only is this tier fat due to the rich GUI it offers, but also due to all the logic code it hosts. The fat client application will either communicate directly with the Data Tier via JDBC, or go through the Middle Tier via a thinly configured Model framework, i.e. it only offers database connectivity and does no additional logic processing in this case (thin). The database again needs to serve simple queries and simple DML-statements (thin) initiated by the fat Client tier. In short all dimensions M, V and C are located in the Client tier.

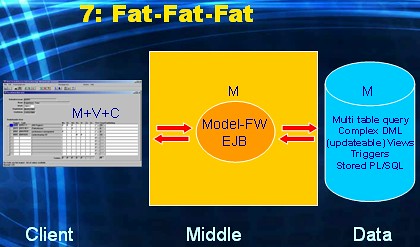
This I would call "client/server the right way". This is what client/server architecture evolved into at the end of the nineties. The M has moved from the Middle tier to the Data tier. The GUI is still rich (i.e. responsive) but all business and data logic is now taking place in the Data tier: the Middle tier (thin) only supports database connectivity from the Client to the Data tier. The database is now fully employed (fat) through the use of stored PL/SQL (functions, procedures, packages), triggers, complex views (updateable, possibly with Instead-of triggers). Also the complexity of data retrieval and manipulation is now dealt with by programming sophisticated SQL queries and DML statements. In short View and Control sit in the Client tier, and Model in the Data tier.
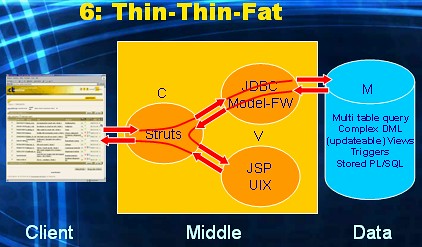
This is again an html-based application (thin Client tier). All dimensions of MVC are available in the Middle tier (fat). Business and data logic processing takes place not only within the Model framework, but also within the Data tier (fat). The big challenge in this alternative is: how do you divide this logic processing? What part do you implement within the Java realm, and what part within the PL/SQL realm of the DBMS? For this alternative to be manageable, you first need to establish a clear set of rules that prescribe how logic is to be divided accross the two tiers.
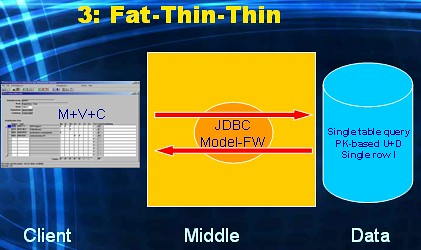
This one is my personal favorite. It is essentially (the popular) alternative one, only the M has now moved from the Middle tier to the Data tier. All business and data logic processing takes place inside the database (fat). The Model framework is deployed only for database connectivity: no additional logic code runs within this framework (thin). Compared to the previous alternative (five), the division of the business and data logic processing has been made 100% in favour of the Data tier. The database is now fully employed (fat) through the use of stored PL/SQL (functions, procedures, packages), triggers, complex views (updateable, possibly with Instead-of triggers). Also the complexity of data retrieval and manipulation is now dealt with by programming sophisticated SQL queries and DML statements. In short View and Control sit in the Middle tier and Model in the Data tier. This alternative is actually what the Helsinki declaration is all about (and I will revisit this, obviously much more, in later posts).
This is what I call the "Run, run, run! As fast as you can" alternative. Business and data logic is distributed among all tiers: within the fat client, within the Model framework and/or EJB layer, and also within the database. The big challenge introduced in alternative five, is even bigger here. Managing application development within this architecture must be a complete nightmare. You'll end up with this approach if you put a PL/SQL wizard, Java evangelist and RIA fan all in the same project team, without adding a architect...
Most Common Approaches
As said before, the most popular approach out there is: Thin-Fat-Thin the JEE way. Second most popular would be Thin-Fat-Fat which I see executed in two subbtle different ways:
Bear with me please. This is fun.
Let's say we have a GrantParent-Parent-Child three-table design. And the enduser needs to be given a report based on Parent rows. Per parent row (P) the result of some aggregation over its child rows (C) needs to be shown. And per parent row a few column values of its grandparent (GP) needs to be shown. So in SQL something of the following structure needs to be developed.
Now what happens in this approach, is that the following API's are requested to be developed in the DBMS:
Obviously calling the DBMS many times has a performance hit (which I will revisit in a future post).
How much more easy would it be to just create a view using the query-text above. And then query the view and display the result set straight on to the page? Bypassing the object class hierarchy in the middle tier alltogether.
To be continued...
- Model code
- View code
- Control code
Number eight, Thin-Thin-Thin, is irrelevant and therefor not shown. I'll discuss each of above seven approaches in this post.
Let's start with number 1: Thin-Fat-Thin.
This is the typical JEE way of creating an HTML-based application. And it is I think by far the most popular approach. Control is implemented for instance with some control-framework (used to be Struts, but I think it's Spring nowadays). Model is implemented with EJB or some model framework (in an Oracle environment: ADF-BC). View is implemented with JSP or some view framework (e.g. UIX, JSF, ...). In this approach the browser displays a (poor) HTML GUI (thin), and sends HTTP requests to the controller. The controller then coordinates the execution of EJB code or model framework code. Inside these all business logic and data logic processing has been implemented (fat). Eventually simple (i.e. single table) queries , or simple (i.e. single row, primary-key based) DML statements are executed towards the database (thin). The controller then determines the next page to be sent back and initiates the View framework to do so. Both Control and View hold no business/data logic, since that would violate the MVC design pattern.
This is "client/server the JEE way". The client-tier runs a fat program (either Applet based, or Java-in-OS based). Control and View are implemented within this fat client-side GUI application. Model is implemented with EJB or some model framework. The client tier is in charge in this alternative (fat): it deals with creating the rich GUI and handling all UI-events (control) on behalf of the user. In this alternative the client delegates the execution of all business logic and data logic processing to EJB code or Model framework code, which is located centrally in the middle tier (fat). The database again only needs to serve simple queries and simple DML-statements (thin) initiated by the fat Model layer. In short, processing for V and C takes place in the Client tier and for M takes place in the Middle tier.
This is "client/server in the early days", pre Oracle7 (when stored pl/sql was not available yet). The application is again either Applet based or Java-in-OS based. The difference with the previous alternative is that all business and data logic is now also implemented within the rich GUI application running on the Client Tier (fat). So not only is this tier fat due to the rich GUI it offers, but also due to all the logic code it hosts. The fat client application will either communicate directly with the Data Tier via JDBC, or go through the Middle Tier via a thinly configured Model framework, i.e. it only offers database connectivity and does no additional logic processing in this case (thin). The database again needs to serve simple queries and simple DML-statements (thin) initiated by the fat Client tier. In short all dimensions M, V and C are located in the Client tier.
This I would call "client/server the right way". This is what client/server architecture evolved into at the end of the nineties. The M has moved from the Middle tier to the Data tier. The GUI is still rich (i.e. responsive) but all business and data logic is now taking place in the Data tier: the Middle tier (thin) only supports database connectivity from the Client to the Data tier. The database is now fully employed (fat) through the use of stored PL/SQL (functions, procedures, packages), triggers, complex views (updateable, possibly with Instead-of triggers). Also the complexity of data retrieval and manipulation is now dealt with by programming sophisticated SQL queries and DML statements. In short View and Control sit in the Client tier, and Model in the Data tier.
This is again an html-based application (thin Client tier). All dimensions of MVC are available in the Middle tier (fat). Business and data logic processing takes place not only within the Model framework, but also within the Data tier (fat). The big challenge in this alternative is: how do you divide this logic processing? What part do you implement within the Java realm, and what part within the PL/SQL realm of the DBMS? For this alternative to be manageable, you first need to establish a clear set of rules that prescribe how logic is to be divided accross the two tiers.
This one is my personal favorite. It is essentially (the popular) alternative one, only the M has now moved from the Middle tier to the Data tier. All business and data logic processing takes place inside the database (fat). The Model framework is deployed only for database connectivity: no additional logic code runs within this framework (thin). Compared to the previous alternative (five), the division of the business and data logic processing has been made 100% in favour of the Data tier. The database is now fully employed (fat) through the use of stored PL/SQL (functions, procedures, packages), triggers, complex views (updateable, possibly with Instead-of triggers). Also the complexity of data retrieval and manipulation is now dealt with by programming sophisticated SQL queries and DML statements. In short View and Control sit in the Middle tier and Model in the Data tier. This alternative is actually what the Helsinki declaration is all about (and I will revisit this, obviously much more, in later posts).
This is what I call the "Run, run, run! As fast as you can" alternative. Business and data logic is distributed among all tiers: within the fat client, within the Model framework and/or EJB layer, and also within the database. The big challenge introduced in alternative five, is even bigger here. Managing application development within this architecture must be a complete nightmare. You'll end up with this approach if you put a PL/SQL wizard, Java evangelist and RIA fan all in the same project team, without adding a architect...
Most Common Approaches
As said before, the most popular approach out there is: Thin-Fat-Thin the JEE way. Second most popular would be Thin-Fat-Fat which I see executed in two subbtle different ways:
- Thin-Fat-Fat where JEE is 100% in the lead. So a class-hierarchy is modelled in the mid tier to support the business and data logic. And object classes are persisted one-on-one to tables in the data tier (this is what happens in Thin-Fat-Thin too). The relational DBMS ends up managing a hierarhical or network database design. Not a match made in heaven. By far not.
And due to "performance considerations" this approach has opportunistic pl/sql code development. Typically (allthough not exclusive) in the area of batch. Of course the SQL (which loves a sound relational database design) written at this point has to deal with a non-relational database design. This typically leads to ugly SQL, and ample reasons for the middle tier programmers to be negative about SQL and DBMS's in general.
- Thin-Fat-Fat where both sides are in the lead. By this I mean: database professionals get to create a relational database design that matches their perceived need of the application, and Java professionals get to create a class hierarchy that matches their perceived need of the application. Since both designs are never the same, this now leads to the infamous impedance mismatch. To connect the two designs the database professionals are asked to develop API´s that bridge the gap. The Java professionals then tweak thier Model framework such that these API´s are called.
Bear with me please. This is fun.
Let's say we have a GrantParent-Parent-Child three-table design. And the enduser needs to be given a report based on Parent rows. Per parent row (P) the result of some aggregation over its child rows (C) needs to be shown. And per parent row a few column values of its grandparent (GP) needs to be shown. So in SQL something of the following structure needs to be developed.
SELECT P.[columns]
,[aggr.function](C.[column])
,GP.[columns]
FROM P, C, GP
WHERE [join conditions P and C]
AND [join conditions P and GP]
GROUP BY [P and GP columns]
Now what happens in this approach, is that the following API's are requested to be developed in the DBMS:
- Give Parent rows
- For a given Parent row ID, give corresponding Child rows
- For a given Parent row ID, give the Grandparent row
Obviously calling the DBMS many times has a performance hit (which I will revisit in a future post).
How much more easy would it be to just create a view using the query-text above. And then query the view and display the result set straight on to the page? Bypassing the object class hierarchy in the middle tier alltogether.
To be continued...
Saturday, March 21, 2009
J2EE and traditional MVC (Part 1)
A short note to new visitors: this blog documents my vision on how to build database web applications. Normally I do this by presenting a two hour presentation know as "A Database Centric Approach to J2EE Application Development". First given at Oracle Openworld 2002. You can find the original paper here (it's the one titled "A First Jdeveloper Project"). Since the Mayday Miracle gathering in Helsinki Finland, the message now carries the flag: The Helsinki Declaration. Over the next few weeks, (probably months) I will document this presentation that has been given many times by now. This is why you will often see powerpoint slides in the blog posts: they are from the actual presentation materials and help me deliver the message in the same way as when giving the presentation.
After presenting the four historical observations (see previous four blog posts), I now proceed in giving my "layman's understanding" of this beast called "JEE".
The(?) JEE Architecture
Here's a way to look at JEE.
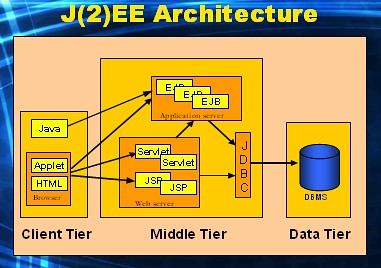
In this architecture we discern three (some say four) "tiers".
The JEE architecture allows us to write code everywhere:
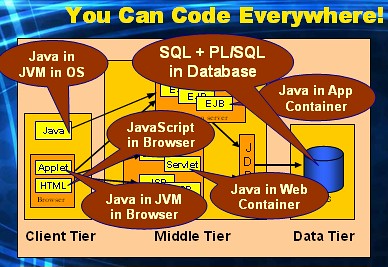
There are many ways you can use JEE to develop a database web application. It all depends on where you want to write the "application logic" for your application. I will return to exactly this particular subject in-depth in upcoming posts.
A very popular design pattern in the JEE world is the Model-View-Control design pattern. Commonly referred to as just MVC. Whenever the end user triggers some event inside the user interface (UI) typically the application code needs to perform something. Code that investigates the event and determines what to do next is called Control code. More often than not, the application will have to query and/or transact data at this time. Code that performs this is called Model code. And finally the UI needs to be refreshed/modified: this is done by View code. The MVC design pattern dictates that these three types of code are not to be merged in one another, but specifically coded into separate modules that communicate with eachother.

Note the "traditional" adverb in the title above. Of course it's not traditional ... , yet! This is a mainstream design pattern used in almost every JEE project. However I believe it should be traditional at some point in time in the near future :-).
To clarify in more detail what the MVC design pattern is about I show my audience two animations. The first one animates how a pre-MVC built web application would handle a browser request.

The browser sends a request to the webserver (due to some event triggered by the end user).
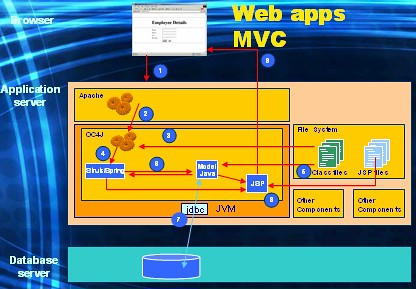
The same scenario described above now goes as follows.
In the next post I will discuss seven (2 power 3 minus 1) alternative ways to use the MVC design pattern. To be continued...
After presenting the four historical observations (see previous four blog posts), I now proceed in giving my "layman's understanding" of this beast called "JEE".
The(?) JEE Architecture
Here's a way to look at JEE.
In this architecture we discern three (some say four) "tiers".
- The data tier
- The middle tier (which holds two "containers")
- The client tier
The JEE architecture allows us to write code everywhere:
- Inside the web container we develop servlets and (old fashioned) JSP's using Java.
- Inside the application container we develop the EJB's in their various sorts, also with Java.
- Inside the browser we use Javascript to increase the user experience of the application.
- Inside the JVM of the browser we develop rich internet applications with Java.
- Inside the JVM offered by the client operating system we can do the same.
- And of course, allthough the JEE architecture does not mention this in any way whatsoever: at the data tier we can write code inside the x-VM of the DBMS. In the case of Oracle this would be the pl/sql-VM.
There are many ways you can use JEE to develop a database web application. It all depends on where you want to write the "application logic" for your application. I will return to exactly this particular subject in-depth in upcoming posts.
A very popular design pattern in the JEE world is the Model-View-Control design pattern. Commonly referred to as just MVC. Whenever the end user triggers some event inside the user interface (UI) typically the application code needs to perform something. Code that investigates the event and determines what to do next is called Control code. More often than not, the application will have to query and/or transact data at this time. Code that performs this is called Model code. And finally the UI needs to be refreshed/modified: this is done by View code. The MVC design pattern dictates that these three types of code are not to be merged in one another, but specifically coded into separate modules that communicate with eachother.
Note the "traditional" adverb in the title above. Of course it's not traditional ... , yet! This is a mainstream design pattern used in almost every JEE project. However I believe it should be traditional at some point in time in the near future :-).
To clarify in more detail what the MVC design pattern is about I show my audience two animations. The first one animates how a pre-MVC built web application would handle a browser request.
The browser sends a request to the webserver (due to some event triggered by the end user).
- Apache accepts the request and,
- Forwards it to the web server container.
- The web container loads a class file from the filesystem
- The web container instantiates an object from this class file, and invokes a method on the object.
- The method then performs all relevant application logic, including,
- rendering the html for the next web page that is to be displayed inside the browser of the end user.
The same scenario described above now goes as follows.
- Browser sends a request.
- Apache forwards the request to the web container.
- The web container loads a Control class.
- And instantiates a Control object.
- The control object investigates the request, and might decide that some querying and/or transacting needs to be done. However it does not perform this, instead it,
- Loads a Model class, instantiates an object from it, and invokes a method on the object.
- This method then performs all necessary model logic and communicates the result back to the control object.
- The control object then determines what the next page of the application should be and loads/instantiates/invokes a view class (eg. a JSP) to perform so.
- The JSP might communicate with the model object to retrieve some cached data that needs to be embedded in the html output stream that it sends back to the browser.
In the next post I will discuss seven (2 power 3 minus 1) alternative ways to use the MVC design pattern. To be continued...
Wednesday, March 18, 2009
The Helsinki declaration: observation 4
So here is the last observation while looking back at 20+ years of (web) database application development. The fourth observation is about the required developer knowledge investment. How much time do you, as a developer, need to invest in learning and taking on the tools with which you can build database (web) applications.
Similar to the DBMS (observation 1) it was real simple to learn the application development tools in the early nineties. All it took was one weekend of reading the documentation and trying out the software tools. In the Oracle scene, Forms 2.0 was really not a too difficult tool. Steve Muench (as far as I know the "inventor" of the Forms product) did a real good job. Of course, it would take a year or two to realize how good the Forms product really was: i.e. what it did for you, so you did not have to worry about that (that = locking, preventing lost-updates, generating insert/update/delete statements, etc.).
Outside the Oracle tools scene you could also opt for "third generation languages" in those days. Turbo Pascal, Lattice C, Fortran and the likes. Combined with Oracle pre compilers, which gave you the ability to embed SQL inside the code, they would typically offer the possibility to implement performant batch-processes.
Then, in the early/mid nineties when (anonymous) PL/SQL was introduced in the database (oracle version 6) Steve gave us Forms 3.0. A huge leap forwards. It also had a local PL/SQL engine. The reference guide for 3.0 was more than twice as thick as the guide for 2.0 or 2.3. Do you see the resemblance with observation 1? It would take a few weeks to become really productive with this tool.
A few years later, moving from character-mode to GUI-mode, (the infamous early releases of) Forms 4.0 was (were) brought to us by Oracle. Which really took till Forms 4.5 to become stable. At this time other (third party) tools, such as Powerbuilder, Uniface, and maybe two or three others that I cannot remember anymore, were "hot" also.
By now the Forms product had reached a level of complexity where using Forms "generators" really became the way to build applications. Generators were already available in the char-mode era (with Forms 3.0). I forgot what the product was called. I think it was Oracle Case 5.0.
These generators added yet another level of complexity to the tool-stack that you, the developer, had to master, in order to deliver database applications. This however was solved by add-on utilities (headstart). Which again just added more complexity, if you ask me. Since you couldn't purge your Forms (builder, design-time) knowledge. A 100% generation was unrealistic, unless you were the actual developer of the headstart toolset. The majority of the projects always required "post-generation" development. And sometimes a lot so. Furthermore there was the wholy grail of keeping the forms re-generate-able. Only very, very, few projects managed to achieve that (and at a very high cost).
I used to be "all round". An application developer more than a DBA. I did both. But I decided to quit being a developer when Case Generator (later called Designer/2000 etc.) became the way to build apps, and move over to the DBA field. I knew forms inside-out, and was able to kick out screens really fast: I did not see how these "generators" were making my job easier. Of course I was already building database applications in a (pre-version-of-the) Helsinki approach.
The developer toolstack then moved to Forms6.0 and Forms6i: webforms. An applet running in your browser, dealing with the (client/server) forms. Obviously this was going nowhere...
Hence, here came J2EE...
Apart from the fact that it was way back to writing low-level code again, it was also code that was hard, no, really very hard, to read and thus, hard-like to maintain.
Over the years J2EE became JEE,. Design patterns and frameworks gave us 'lessons learned' and 'abstraction layers'. Writing low-level Java code was replaced by configuring frameworks. Of course you still have to know and understand Java, like you still had to know and understand the Forms builder product. Not only Java, but more technologies: html, Javascript, XML, cascading style sheets, etc. And let's not forget the frameworks-du-jour.
So this is observation 4:
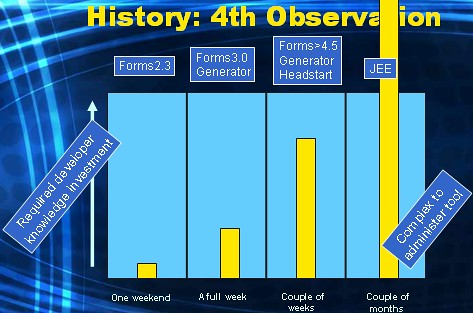
The ratio of "required knowledge investment" versus "produced output" for developers is way off the scale nowadays. For the more young people out there reading this blog: you have no idea with how little (compared to now) technological knowledge we were able to build database applications in the past. I also suspect that you find it very hard to keep up with, and to have broad and deep knowledge of, todays "tools" that you are supposed to use when building these kind of (web) apps. I far from envy you. It must be horrific.
There is no way one person can grasp all the technological knowledge that is required to build these kind of applications today. This is why development teams now always consist of several (different) specialists. And of course one "architect". The person to mediate and achieve consensus between all involved specialists. In my presentation I call the architect the person to keep TPTAWTSHHTF (*) away.
This is the last observation I wanted to point out.
In summary, here are all four observations:
First we need to spend some time on J(2)EE.
Stay tuned.
(*: The Person That Arrives When The Shit Has Hit The Fan)
Similar to the DBMS (observation 1) it was real simple to learn the application development tools in the early nineties. All it took was one weekend of reading the documentation and trying out the software tools. In the Oracle scene, Forms 2.0 was really not a too difficult tool. Steve Muench (as far as I know the "inventor" of the Forms product) did a real good job. Of course, it would take a year or two to realize how good the Forms product really was: i.e. what it did for you, so you did not have to worry about that (that = locking, preventing lost-updates, generating insert/update/delete statements, etc.).
Outside the Oracle tools scene you could also opt for "third generation languages" in those days. Turbo Pascal, Lattice C, Fortran and the likes. Combined with Oracle pre compilers, which gave you the ability to embed SQL inside the code, they would typically offer the possibility to implement performant batch-processes.
Then, in the early/mid nineties when (anonymous) PL/SQL was introduced in the database (oracle version 6) Steve gave us Forms 3.0. A huge leap forwards. It also had a local PL/SQL engine. The reference guide for 3.0 was more than twice as thick as the guide for 2.0 or 2.3. Do you see the resemblance with observation 1? It would take a few weeks to become really productive with this tool.
A few years later, moving from character-mode to GUI-mode, (the infamous early releases of) Forms 4.0 was (were) brought to us by Oracle. Which really took till Forms 4.5 to become stable. At this time other (third party) tools, such as Powerbuilder, Uniface, and maybe two or three others that I cannot remember anymore, were "hot" also.
By now the Forms product had reached a level of complexity where using Forms "generators" really became the way to build applications. Generators were already available in the char-mode era (with Forms 3.0). I forgot what the product was called. I think it was Oracle Case 5.0.
These generators added yet another level of complexity to the tool-stack that you, the developer, had to master, in order to deliver database applications. This however was solved by add-on utilities (headstart). Which again just added more complexity, if you ask me. Since you couldn't purge your Forms (builder, design-time) knowledge. A 100% generation was unrealistic, unless you were the actual developer of the headstart toolset. The majority of the projects always required "post-generation" development. And sometimes a lot so. Furthermore there was the wholy grail of keeping the forms re-generate-able. Only very, very, few projects managed to achieve that (and at a very high cost).
I used to be "all round". An application developer more than a DBA. I did both. But I decided to quit being a developer when Case Generator (later called Designer/2000 etc.) became the way to build apps, and move over to the DBA field. I knew forms inside-out, and was able to kick out screens really fast: I did not see how these "generators" were making my job easier. Of course I was already building database applications in a (pre-version-of-the) Helsinki approach.
The developer toolstack then moved to Forms6.0 and Forms6i: webforms. An applet running in your browser, dealing with the (client/server) forms. Obviously this was going nowhere...
Hence, here came J2EE...
Apart from the fact that it was way back to writing low-level code again, it was also code that was hard, no, really very hard, to read and thus, hard-like to maintain.
Over the years J2EE became JEE,. Design patterns and frameworks gave us 'lessons learned' and 'abstraction layers'. Writing low-level Java code was replaced by configuring frameworks. Of course you still have to know and understand Java, like you still had to know and understand the Forms builder product. Not only Java, but more technologies: html, Javascript, XML, cascading style sheets, etc. And let's not forget the frameworks-du-jour.
So this is observation 4:
The ratio of "required knowledge investment" versus "produced output" for developers is way off the scale nowadays. For the more young people out there reading this blog: you have no idea with how little (compared to now) technological knowledge we were able to build database applications in the past. I also suspect that you find it very hard to keep up with, and to have broad and deep knowledge of, todays "tools" that you are supposed to use when building these kind of (web) apps. I far from envy you. It must be horrific.
There is no way one person can grasp all the technological knowledge that is required to build these kind of applications today. This is why development teams now always consist of several (different) specialists. And of course one "architect". The person to mediate and achieve consensus between all involved specialists. In my presentation I call the architect the person to keep TPTAWTSHHTF (*) away.
This is the last observation I wanted to point out.
In summary, here are all four observations:
- The DBMS is finally mature, hence we-do-not-use it anymore.
- We still develop UFI's, but in a lot more complex manner.
- There is an ongoing YAFET technology explosion.
- The investment required for developers to become productive, has gone through the roof.
First we need to spend some time on J(2)EE.
Stay tuned.
(*: The Person That Arrives When The Shit Has Hit The Fan)
Saturday, March 14, 2009
The Helsinki declaration: observation 3 (Yafets)
After observation 1 "we-do-not-use-the-feature-rich-DBMS", and observation 2 "we-are-still-delivering-UFIs-only-in-ways-much-more-complicated-than-we-used-to-do-so", let's move on to the third observation on 20+ years of database application development. As you will see, all observations are (of course) somewhat related. They each just emphasize a different symptom of a single shared underlying trend.
The third observation is about the technology explosion that happened in the last decade. Here's an overview taken from my "part 1" presentation of the available technologies. And yes, I'm aware that there's apples and pears on this overview. It just illustrates a point I want to make.

If you want to build a database web application nowadays you are faced with a couple of (tough) choices to make. There is an ongoing explosion of technology choices available outside the DBMS. New technology enters the arena every six to nine months. Recently introduced technology silently disappears within a few years. I refer to these as technologies du-jour: hot today, forgotten tomorrow. I even have an acronym for them: YAFET's.
Do we really need all these technologies? Better yet: did our customers ask for these? I acknowledge the fact that applications today look different than applications one or two decades ago. For one we moved from character mode to GUI mode (Observation 2). And of course today's applications have features that were technologically impossible in the past. But I also believe that the majority of our customers still ask for applications that are in essence the same as 10-20 years ago (I'll come back to this later). And this unchanged demand doesn't justify the observed technology explosion, if you ask me.
There is one more observation to go (which is closely related to this one).
Stay tuned.
The third observation is about the technology explosion that happened in the last decade. Here's an overview taken from my "part 1" presentation of the available technologies. And yes, I'm aware that there's apples and pears on this overview. It just illustrates a point I want to make.
If you want to build a database web application nowadays you are faced with a couple of (tough) choices to make. There is an ongoing explosion of technology choices available outside the DBMS. New technology enters the arena every six to nine months. Recently introduced technology silently disappears within a few years. I refer to these as technologies du-jour: hot today, forgotten tomorrow. I even have an acronym for them: YAFET's.
- Yet Another Front End Technology
Do we really need all these technologies? Better yet: did our customers ask for these? I acknowledge the fact that applications today look different than applications one or two decades ago. For one we moved from character mode to GUI mode (Observation 2). And of course today's applications have features that were technologically impossible in the past. But I also believe that the majority of our customers still ask for applications that are in essence the same as 10-20 years ago (I'll come back to this later). And this unchanged demand doesn't justify the observed technology explosion, if you ask me.
There is one more observation to go (which is closely related to this one).
Stay tuned.
Thursday, March 12, 2009
The Helsinki declaration: observation 2
To illustrate the second observation, let's take a look at the following quadrant. It maps character-mode / GUI-mode applications against stateless / statefull underlying protocol.
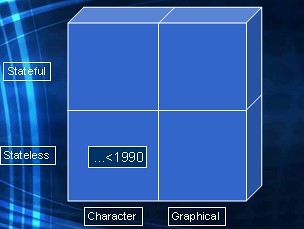
At the end of the eighties the bottom-left square, is were we were. Database applications were provided to endusers who were sitting behind a dumb character-mode terminal, 25 by 40 characters, maybe 25 by 80.The backend mainframe or mini computer would spit out a form to the terminal. The enduser could tab through fields, change data, and then hit the infamous SEND key (the only worn down key that didn't show anymore what it was for). While tabbing through the fields no communication with the backend server was possible. The SEND would submit the whole form back to the server, process it, and generate a new form back to the enduser. Those were the eighties.
Enter the early nineties, the dawn of the client-server era.
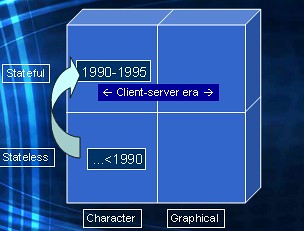
The user now has a PC on the desk. I.e. a machine with a local CPU. We're still in character mode. But, big but, the user is not looking at a static form, but at the screen output generated by a "client"program. There is now code that actually runs on the CPU of the users' PC. And this program has a dedicated connection to the server, open to be used at all times. So while the user is tabbing through fields the program can communicate to the server, typically to validate user input in a early stage. The uses was experiencing a very responsive application. The program might change the user interface on-the-fly without going back and forth to the server. When the user is done changing the data, he/she presses a Commit key (which would ussually be mapped to one of the function keys F1-F10). This would then cause the client program to compose and submit a transaction to the server.
During the nineties the only thing that really changed, is that the user interface went from character mode to graphical mode.
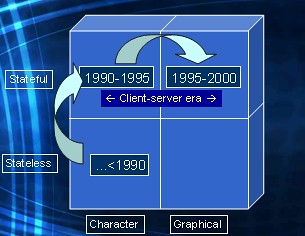
The dominant client operating system MS-DOS was replaced by Windows 3.11, NT, Win 95, etc.
The internet now became available. Browser wars were going on. And at the dawn of the new millenium browsers became the platform of choice to deliver database applications to end users. In terms of our quadrant this meant a shift to the bottom right square.
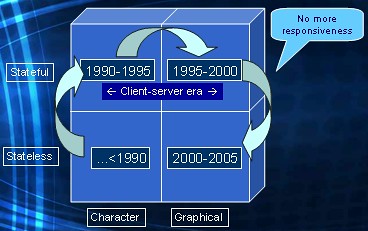
Beware: a browser brought us back to a stateless protocol (http). It is in essence a device that can display a graphical form. As opposed to the dumb terminal at the end of the eighties that was displaying a character form. This also caused lots of complaints from our endusers, who had gotten used to responsive (client/server) database applications. This was countered by introducing Javascript running inside the browser. In the early stages a bit unstructured, later on (nowadays) by using techniques such as Ajax, partial page refresh, dynamic html, etc. So we countered the loss of responsiveness by introducing more complexity inside the browser.

Rich (responsive) internet applications (RIA) are the buzzword now. Enter the third dimension. I sometimes refer to it as "complexity". Complexity not only on the client, but also between the client and the server. We still have the database server way at the end, but in between we now also have webservers and application servers.
So we are still delivering UFI's (User Friendly Interfaces) to our end user, but in ways that are much more complex than they have ever been. KISS is out, MICS (make it complex stupid) is hot.
Which leads us to the third observation. To follow soon.
At the end of the eighties the bottom-left square, is were we were. Database applications were provided to endusers who were sitting behind a dumb character-mode terminal, 25 by 40 characters, maybe 25 by 80.The backend mainframe or mini computer would spit out a form to the terminal. The enduser could tab through fields, change data, and then hit the infamous SEND key (the only worn down key that didn't show anymore what it was for). While tabbing through the fields no communication with the backend server was possible. The SEND would submit the whole form back to the server, process it, and generate a new form back to the enduser. Those were the eighties.
Enter the early nineties, the dawn of the client-server era.
The user now has a PC on the desk. I.e. a machine with a local CPU. We're still in character mode. But, big but, the user is not looking at a static form, but at the screen output generated by a "client"program. There is now code that actually runs on the CPU of the users' PC. And this program has a dedicated connection to the server, open to be used at all times. So while the user is tabbing through fields the program can communicate to the server, typically to validate user input in a early stage. The uses was experiencing a very responsive application. The program might change the user interface on-the-fly without going back and forth to the server. When the user is done changing the data, he/she presses a Commit key (which would ussually be mapped to one of the function keys F1-F10). This would then cause the client program to compose and submit a transaction to the server.
During the nineties the only thing that really changed, is that the user interface went from character mode to graphical mode.
The dominant client operating system MS-DOS was replaced by Windows 3.11, NT, Win 95, etc.
The internet now became available. Browser wars were going on. And at the dawn of the new millenium browsers became the platform of choice to deliver database applications to end users. In terms of our quadrant this meant a shift to the bottom right square.
Beware: a browser brought us back to a stateless protocol (http). It is in essence a device that can display a graphical form. As opposed to the dumb terminal at the end of the eighties that was displaying a character form. This also caused lots of complaints from our endusers, who had gotten used to responsive (client/server) database applications. This was countered by introducing Javascript running inside the browser. In the early stages a bit unstructured, later on (nowadays) by using techniques such as Ajax, partial page refresh, dynamic html, etc. So we countered the loss of responsiveness by introducing more complexity inside the browser.
Rich (responsive) internet applications (RIA) are the buzzword now. Enter the third dimension. I sometimes refer to it as "complexity". Complexity not only on the client, but also between the client and the server. We still have the database server way at the end, but in between we now also have webservers and application servers.
So we are still delivering UFI's (User Friendly Interfaces) to our end user, but in ways that are much more complex than they have ever been. KISS is out, MICS (make it complex stupid) is hot.
Which leads us to the third observation. To follow soon.
The Helsinki declaration: observation 1
So why is this blog called the Helsinki Declaration? Obviously it has nothing todo with the real Declaration of Helsinki. Hence the "IT-version" postfix in the title above. In line with the text of the WMA-version, we could describe the IT-version as follows:
"A set of principles for the IT-community regarding (database) application development"
Or maybe just: my vision on how database applications should be architected and implemented. Previous titles used to bring this message, were:
All rather dull titles, not? So ever since Miracle Mayday 2008 (where I had presented my vision yet again) which was held in Helsinki, Finland, and with the help of Mogens (after a couple of beers) the official title of this message has been set to "The Helsinki Declaration". There you have it, as he would have said.
A bit of history.
Before explaining what the declaration is all about, I usually start by describing a few observations as I have experienced them in the 20+ years of my ride on the Oracle wave. Here is observation 1.

We are in the year 1987. Oracle version 4. Above a picture of the full documentation set way back then. The arrow is pointing towards the chapter titled "DBA guide". The only chapter on the database: all other chapters dealt with "tools outside the database" such as: import/export, RPT/RPF, IAF/IAG (predecessor of SQLForms), etc.
Here's another one.

As you can see from the abundant use of white-space, there wasn't a whole lot of documentation to read. In fact you could study the full documentation set over weekend. Be ignorant on Friday afternoon. And a full-fledged Oracle expert on Monday morning.
I do not have a picture of the version 5 documentation set. But here's a picture of the (full) version 6 documentation set.

The arrow now points to the "Oracle RDBMS database administrators guide". A thick book which would take considerably more than a weekend to study. The other thick(er) one you see a bit more to the left, is the "SQLForms3.0 developer's reference".
Next up Oracle7:

Now mind you. This is *not* the full documentation set anymore. It's just the stuff for the database. So what was just one book in version 6, now has exploded into a dozen of books with Oracle7. Oracle7 of course was a huge leap forward at that time and started the "golden years" of the mid and late nineties for Oracle.
Finally I have a picture of the Oracle8i documentation set (database only again).

As you can see it doubled the amount of stuff to read compared to Oracle7. I (and my customers) stopped purchasing hardcopies of the documenation for Oracle9i and later versions. Pricing of harcopy documentation went up dramatically as I recall: Oracle wanted us to use the online documentation. Which we all started doing. But I bet that (had they been available) hardcopy versions of the documentation sets of 9i, 10G and 11G, would continue to double in thickness for every major release.
In the past twenty years we observe that the functionality (features) that is available to us inside the DBMS, has exponentially grown. These features enabled us to build database applications. Which is what we all started doing in the booming nineties. At first, with Oracle versions 6 and below which didn't offer much functionality yet inside the DBMS, other than SQL. I know, there was anonymous PL/SQL, but that was hardly used. We had to stuff all functionality into the client and built fat (sqlforms30) client applications. But as more useable features became available, which was definitely the case with the advent of Oracle7, we started pushing application logic into the DBMS (stored procs etc.). Why? Because we discovered that this created:
So as features became available to us inside the DBMS, we started using them.
But then at the dawn of the new millenium, something happened. And that something misteriously made the role of the DBMS inside a database application project diminish to insignificant. Of course I'm talking about Java and J2EE here now, to which I will return in a later post. But as of the new millenium we are pushing all application logic out of the DBMS into middle tier servers. The functionality of stuff implemented outside the DBMS has exploded, and the feature rich DBMS is hardly used for anything but row-storage. Here's a picture from my presentation showing this.
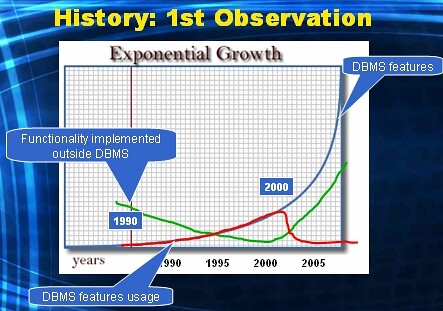
The blue line shows the exponential growth of features available to us inside the DBMS.
The red line shows how we have adopted those features in the nineties, and ceased using them anymore in the new millenium.
The green line (follows from the red line) shows what part of a database application is implemented with technologies outside the DBMS.
This is the first observation. Three more to follow.
"A set of principles for the IT-community regarding (database) application development"
Or maybe just: my vision on how database applications should be architected and implemented. Previous titles used to bring this message, were:
- "A database centric approach to J2EE application development"
- "A database centric approach to web application development"
- "Long live the fat database"
- "Harvesting the advantages of a database centric development approach"
- "Fat databases: a layered approach"
All rather dull titles, not? So ever since Miracle Mayday 2008 (where I had presented my vision yet again) which was held in Helsinki, Finland, and with the help of Mogens (after a couple of beers) the official title of this message has been set to "The Helsinki Declaration". There you have it, as he would have said.
A bit of history.
Before explaining what the declaration is all about, I usually start by describing a few observations as I have experienced them in the 20+ years of my ride on the Oracle wave. Here is observation 1.
We are in the year 1987. Oracle version 4. Above a picture of the full documentation set way back then. The arrow is pointing towards the chapter titled "DBA guide". The only chapter on the database: all other chapters dealt with "tools outside the database" such as: import/export, RPT/RPF, IAF/IAG (predecessor of SQLForms), etc.
Here's another one.
As you can see from the abundant use of white-space, there wasn't a whole lot of documentation to read. In fact you could study the full documentation set over weekend. Be ignorant on Friday afternoon. And a full-fledged Oracle expert on Monday morning.
I do not have a picture of the version 5 documentation set. But here's a picture of the (full) version 6 documentation set.
The arrow now points to the "Oracle RDBMS database administrators guide". A thick book which would take considerably more than a weekend to study. The other thick(er) one you see a bit more to the left, is the "SQLForms3.0 developer's reference".
Next up Oracle7:
Now mind you. This is *not* the full documentation set anymore. It's just the stuff for the database. So what was just one book in version 6, now has exploded into a dozen of books with Oracle7. Oracle7 of course was a huge leap forward at that time and started the "golden years" of the mid and late nineties for Oracle.
Finally I have a picture of the Oracle8i documentation set (database only again).
As you can see it doubled the amount of stuff to read compared to Oracle7. I (and my customers) stopped purchasing hardcopies of the documenation for Oracle9i and later versions. Pricing of harcopy documentation went up dramatically as I recall: Oracle wanted us to use the online documentation. Which we all started doing. But I bet that (had they been available) hardcopy versions of the documentation sets of 9i, 10G and 11G, would continue to double in thickness for every major release.
In the past twenty years we observe that the functionality (features) that is available to us inside the DBMS, has exponentially grown. These features enabled us to build database applications. Which is what we all started doing in the booming nineties. At first, with Oracle versions 6 and below which didn't offer much functionality yet inside the DBMS, other than SQL. I know, there was anonymous PL/SQL, but that was hardly used. We had to stuff all functionality into the client and built fat (sqlforms30) client applications. But as more useable features became available, which was definitely the case with the advent of Oracle7, we started pushing application logic into the DBMS (stored procs etc.). Why? Because we discovered that this created:
- More manageable applications
- More performant applications
So as features became available to us inside the DBMS, we started using them.
But then at the dawn of the new millenium, something happened. And that something misteriously made the role of the DBMS inside a database application project diminish to insignificant. Of course I'm talking about Java and J2EE here now, to which I will return in a later post. But as of the new millenium we are pushing all application logic out of the DBMS into middle tier servers. The functionality of stuff implemented outside the DBMS has exploded, and the feature rich DBMS is hardly used for anything but row-storage. Here's a picture from my presentation showing this.
The blue line shows the exponential growth of features available to us inside the DBMS.
The red line shows how we have adopted those features in the nineties, and ceased using them anymore in the new millenium.
The green line (follows from the red line) shows what part of a database application is implemented with technologies outside the DBMS.
This is the first observation. Three more to follow.
Wednesday, March 11, 2009
@Hotsos 2009: Starting this blog
So here I am at Hotsos Symposium 2009. I've presented my vision on how to build "Window-on-Data" applications, yet again. I think it must have been the tenth time or so, ever since 2002, when I first presented the basics of this approach at Oracle Openworld. And of course again I was preaching in front of the choir. It has since evolved into a full 2-hour presentation, or rather a Part 1 and Part 2 presentation each taking one hour. Part 1 puts the way we (the IT-industry) have been building database applications the past 20+ years in perspective, and draws a couple of conclusions from that. Part 2 then shows how to ideally build these type of applications. On this weblog I intend to publish the approach and also hope to regularly post new insights and/or ideas around the approach.
Stay tuned as more content should follow shortly.
Stay tuned as more content should follow shortly.
Subscribe to:
Posts (Atom)