- Model code
- View code
- Control code
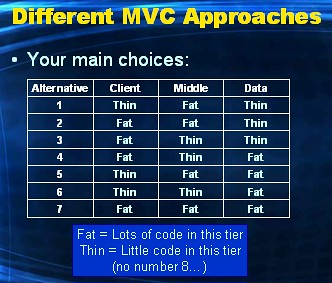
Number eight, Thin-Thin-Thin, is irrelevant and therefor not shown. I'll discuss each of above seven approaches in this post.
Let's start with number 1: Thin-Fat-Thin.
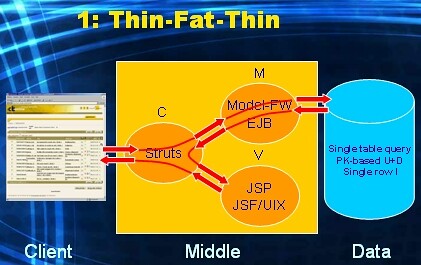
This is the typical JEE way of creating an HTML-based application. And it is I think by far the most popular approach. Control is implemented for instance with some control-framework (used to be Struts, but I think it's Spring nowadays). Model is implemented with EJB or some model framework (in an Oracle environment: ADF-BC). View is implemented with JSP or some view framework (e.g. UIX, JSF, ...). In this approach the browser displays a (poor) HTML GUI (thin), and sends HTTP requests to the controller. The controller then coordinates the execution of EJB code or model framework code. Inside these all business logic and data logic processing has been implemented (fat). Eventually simple (i.e. single table) queries , or simple (i.e. single row, primary-key based) DML statements are executed towards the database (thin). The controller then determines the next page to be sent back and initiates the View framework to do so. Both Control and View hold no business/data logic, since that would violate the MVC design pattern.
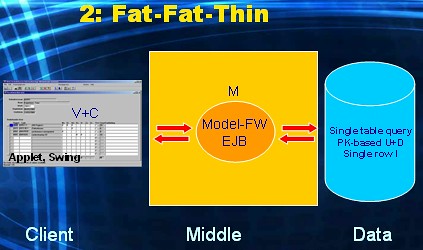
This is "client/server the JEE way". The client-tier runs a fat program (either Applet based, or Java-in-OS based). Control and View are implemented within this fat client-side GUI application. Model is implemented with EJB or some model framework. The client tier is in charge in this alternative (fat): it deals with creating the rich GUI and handling all UI-events (control) on behalf of the user. In this alternative the client delegates the execution of all business logic and data logic processing to EJB code or Model framework code, which is located centrally in the middle tier (fat). The database again only needs to serve simple queries and simple DML-statements (thin) initiated by the fat Model layer. In short, processing for V and C takes place in the Client tier and for M takes place in the Middle tier.
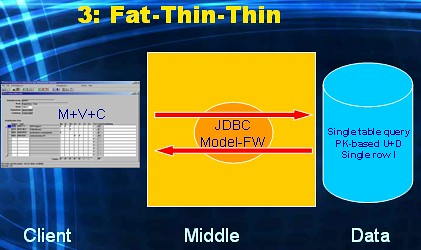
This is "client/server in the early days", pre Oracle7 (when stored pl/sql was not available yet). The application is again either Applet based or Java-in-OS based. The difference with the previous alternative is that all business and data logic is now also implemented within the rich GUI application running on the Client Tier (fat). So not only is this tier fat due to the rich GUI it offers, but also due to all the logic code it hosts. The fat client application will either communicate directly with the Data Tier via JDBC, or go through the Middle Tier via a thinly configured Model framework, i.e. it only offers database connectivity and does no additional logic processing in this case (thin). The database again needs to serve simple queries and simple DML-statements (thin) initiated by the fat Client tier. In short all dimensions M, V and C are located in the Client tier.

This I would call "client/server the right way". This is what client/server architecture evolved into at the end of the nineties. The M has moved from the Middle tier to the Data tier. The GUI is still rich (i.e. responsive) but all business and data logic is now taking place in the Data tier: the Middle tier (thin) only supports database connectivity from the Client to the Data tier. The database is now fully employed (fat) through the use of stored PL/SQL (functions, procedures, packages), triggers, complex views (updateable, possibly with Instead-of triggers). Also the complexity of data retrieval and manipulation is now dealt with by programming sophisticated SQL queries and DML statements. In short View and Control sit in the Client tier, and Model in the Data tier.
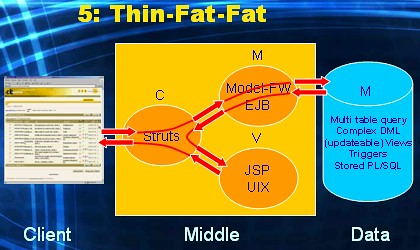
This is again an html-based application (thin Client tier). All dimensions of MVC are available in the Middle tier (fat). Business and data logic processing takes place not only within the Model framework, but also within the Data tier (fat). The big challenge in this alternative is: how do you divide this logic processing? What part do you implement within the Java realm, and what part within the PL/SQL realm of the DBMS? For this alternative to be manageable, you first need to establish a clear set of rules that prescribe how logic is to be divided accross the two tiers.
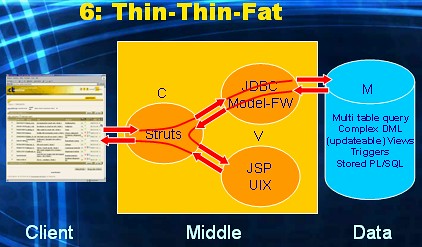
This one is my personal favorite. It is essentially (the popular) alternative one, only the M has now moved from the Middle tier to the Data tier. All business and data logic processing takes place inside the database (fat). The Model framework is deployed only for database connectivity: no additional logic code runs within this framework (thin). Compared to the previous alternative (five), the division of the business and data logic processing has been made 100% in favour of the Data tier. The database is now fully employed (fat) through the use of stored PL/SQL (functions, procedures, packages), triggers, complex views (updateable, possibly with Instead-of triggers). Also the complexity of data retrieval and manipulation is now dealt with by programming sophisticated SQL queries and DML statements. In short View and Control sit in the Middle tier and Model in the Data tier. This alternative is actually what the Helsinki declaration is all about (and I will revisit this, obviously much more, in later posts).
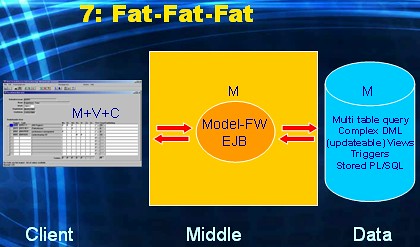
This is what I call the "Run, run, run! As fast as you can" alternative. Business and data logic is distributed among all tiers: within the fat client, within the Model framework and/or EJB layer, and also within the database. The big challenge introduced in alternative five, is even bigger here. Managing application development within this architecture must be a complete nightmare. You'll end up with this approach if you put a PL/SQL wizard, Java evangelist and RIA fan all in the same project team, without adding a architect...
Most Common Approaches
As said before, the most popular approach out there is: Thin-Fat-Thin the JEE way. Second most popular would be Thin-Fat-Fat which I see executed in two subbtle different ways:
- Thin-Fat-Fat where JEE is 100% in the lead. So a class-hierarchy is modelled in the mid tier to support the business and data logic. And object classes are persisted one-on-one to tables in the data tier (this is what happens in Thin-Fat-Thin too). The relational DBMS ends up managing a hierarhical or network database design. Not a match made in heaven. By far not.
And due to "performance considerations" this approach has opportunistic pl/sql code development. Typically (allthough not exclusive) in the area of batch. Of course the SQL (which loves a sound relational database design) written at this point has to deal with a non-relational database design. This typically leads to ugly SQL, and ample reasons for the middle tier programmers to be negative about SQL and DBMS's in general.
- Thin-Fat-Fat where both sides are in the lead. By this I mean: database professionals get to create a relational database design that matches their perceived need of the application, and Java professionals get to create a class hierarchy that matches their perceived need of the application. Since both designs are never the same, this now leads to the infamous impedance mismatch. To connect the two designs the database professionals are asked to develop API´s that bridge the gap. The Java professionals then tweak thier Model framework such that these API´s are called.
Bear with me please. This is fun.
Let's say we have a GrantParent-Parent-Child three-table design. And the enduser needs to be given a report based on Parent rows. Per parent row (P) the result of some aggregation over its child rows (C) needs to be shown. And per parent row a few column values of its grandparent (GP) needs to be shown. So in SQL something of the following structure needs to be developed.
SELECT P.[columns]
,[aggr.function](C.[column])
,GP.[columns]
FROM P, C, GP
WHERE [join conditions P and C]
AND [join conditions P and GP]
GROUP BY [P and GP columns]
Now what happens in this approach, is that the following API's are requested to be developed in the DBMS:
- Give Parent rows
- For a given Parent row ID, give corresponding Child rows
- For a given Parent row ID, give the Grandparent row
Obviously calling the DBMS many times has a performance hit (which I will revisit in a future post).
How much more easy would it be to just create a view using the query-text above. And then query the view and display the result set straight on to the page? Bypassing the object class hierarchy in the middle tier alltogether.
To be continued...
An expanded version of your example that I've seen a lot is:
ReplyDelete1) The middle tier will then call the first API.
2) The child rows get changed by some other process
3) And per Parent row it will call the 2nd API and perform the aggregation in the middle tier.
4) The grand parent row gets changed by some other process
5) And per Parent row it will call the 3rd API.
6) Inside Java the results of calling these API's are then merged to form the set of rows...
7) Somebody notices the inconsitencies
8) Time is spent bashing Oracle
9) Triggers get added to the tables to denote when updates occur between steps 1,3 and 5
10) If updates have occured the Java restarts the calls
11) The application is deemed to be slow
12) Time is spent bashing Oracle
13) Repeat until the next architecture buzzwords come along and everything is rewritten.
..
The alternative is, as you suggest, to create a view to perform all of the logic and show everything at once. Oracle's
table functions make this even more powerful. Somehow Java folks dont trust this though.
very nice and thrilling story so far !
ReplyDeleteI'll keep reading (and enjoying)
"A brief history of IT development" ;)
ReplyDeleteI enjoyed your summary of the last 2 decade - my sentiments exactly.
It's a shame the DB seems to have taken a back seat to front end development.
I think the numerous frameworks are still good, but a project should still
have a solid DB design to build upon, which is sometimes pushed to the side.
It's a pain to sort out data quality issues after the fact when a project partially
implemented DB constraints and foreign keys, preferring middle tier business logic.
Seems to overlook the reason why RDBMS came about.
Look forward to your next installment!
@anonymous1: wonderful expansion of my example, thank you. Table functions are indeed a powerful tool. They come at second place for me, right after ref-cursors.
ReplyDelete@Sokrates: I'll do my best to keep up the post frequency. Lot's of powerpoint pages to go still... :-)
@anonymous2: "seems to overlook the reason..." Exactly, spot on. Next post will be about that.
Very interesting Toon, and so very true.
ReplyDeletei believe its worth mentioning that j2ee was devised for the sole purpose of solving some of the hardest (and rarest) computing problems. particularly, systems that can be defined as integrators, aggregators and jewels. j2ee is complete overkill for stovepipe systems.
ReplyDeleteadditionally, the problems of integrators, aggregators and jewels can be solved easily using intelligent back end systems… oracle being a primary example.
unfortunately, not even oracle actually promotes this view… as they have found the middle tier market a ripe place for profit! I was at a apex talk recently held by oracle where they kept saying that it wasn’t an enterprise solution. when pressured as to why it wasn’t an enterprise solution they just grumbled… fact is, it completely bypasses their middle tier suite of tools. but I digress…
"when pressured as to why it wasn’t..."
ReplyDeleteStrictly speaking you were asking the wrong question...
Your mentioning of J2EE being devised to solve the hardest (and rarest) computing problems, is very interesting. Makes you wonder why-o-why everybody adopted J2EE to solve the Window-on-Data application "problem".
Ignorance?
"They have found the middle tier market a ripe place for profit!"
Exactly my point here.
Great! Exactly what I'm thinking about, but so structured and organized
ReplyDeleteI appreciate your blog ,Very Nice
ReplyDelete.Net Online Training Hyderabad